 VN
VN
 EN
EN
Kỷ nguyên của công nghệ thông minh
Khi nói về AI, chúng ta chủ yếu nói về học máy: một lĩnh vực phụ của khoa học máy tính có ít nhất từ những năm 1950.Các phương pháp phổ biến hiện nay để xây dựng công cụ đề xuất, phân loại, hoặc dự đoán lưu lượng truy cập về cơ bản không khác với các thuật toán được phát minh ra từ nhiều thập kỷ trước.
Vậy tại sao đến tận bây giờ mới có sự quan tâm và đầu tư lớn vào trí tuệ nhân tạo? Câu trả lời đơn giản nằm ở
dữ liệu
. Với sự phát triển mạnh mẽ của Internet và các thiết bị di động, mạng xã hội, GPS, camera, mua hàng trực tuyến, v.v mỗi bước đi, mỗi cú click của con người đều trở thành một kho dữ liệu sống để đào tạo các mô hình học máy.
“Với một tập hợp dữ liệu đủ lớn, máy tính có thể xem xét đặc trưng các mối quan hệ khác nhau để ra quyết định thay con người”, anh Mai Tấn Tài, phó giáo sư khoa học máy tính tại Đại học Thành phố Dublin (Ireland), nhận xét trong buổi tọa đàm “Rủi ro đạo đức với trí tuệ nhân tạo” do
Tia Sáng
tổ chức ngày 28/7. Đây là một trong những cuộc thảo luận công cộng đầu tiên đặt trọng tâm vào đạo đức AI ở Việt Nam.

Cuộc thảo luận ngày nay không còn là câu hỏi liệu AI có tham gia vào đời sống xã hội hay không và bằng cách nào - bởi thực tế chúng đã
ở đây
trong mọi hoạt động hàng ngày.
Khi chúng ta đặt đồ ăn trên NOW hoặc LoShip, có một thuật toán giúp trả về các nhà hàng hoặc món ăn gần nhất sau khi được lọc qua một bộ lọc vị trí và từ khóa. Khi đặt xe từ Grab hoặc Be, thuật toán có thể dự báo nhu cầu và thông báo tới người lái xe gần đó, làm giảm thời gian đến dự kiến. Khi lướt Facebook hoặc xem phim trên Netflix, các công cụ AI ở phía dưới sẽ phân tích sở thích của người dùng và gợi ý những nội dung mà chúng ta có khả năng thích nhiều hơn – nhờ vậy ta không còn phải mất hàng giờ sàng lọc thông tin để quyết định những gì mình muốn xem.
Trí tuệ nhân tạo cũng đang được sử dụng ngày càng nhiều trong lĩnh vực tài chính-ngân hàng, fintech, chăm sóc sức khỏe, giáo dục, thương mại điện tử, marketing v.v. Giờ đây, chúng ta có thể tiếp cận với những dịch vụ được cá nhân hóa cao mọi lúc, mọi nơi.
Sự cần thiết phải điều chỉnh AI
Mặc dù tạo ra nhiều lợi ích nhưng AI cũng không phải không có thiếu sót của mình. Các vấn đề mà AI tạo ra đang và sẽ ảnh hưởng đáng kể đến xã hội, việc làm và quyền công dân của mỗi người.
Trong bộ phim khoa học viễn tưởng
I, Robot (2004)
lấy bối cảnh năm 2035, nhân vật chính thám tử Del Spooner ghét những robot phục vụ nhân loại vì anh ta đã chứng kiến một robot sử dụng dữ liệu logic và tỷ lệ sống sót để cứu anh ta khỏi chết đuối, trong khi để một cô gái trẻ chết. Tuy nhiên, chúng ta có thể không cần đợi thêm 12 năm nữa, điều tương tự đã xảy ra vào thời điểm niềm tin vào xe tự lái đang ở mức cao nhất. Vào tháng 5/2018, một chiếc
Uber tự lái
đã đâm vào một người đang dắt một chiếc xe đạp qua đường ở Arizona, dẫn đến cái chết của cô. Uber không phải đối mặt với bất kỳ cáo buộc nào với lý do “không có cơ sở để chịu trách nhiệm hình sự”.
Trong cả hai trường hợp, không nhất thiết là AI trở nên có tri giác và phát triển xu hướng độc ác. Nó chỉ là kết quả của một số sai sót về quy trình an toàn và những thành kiến thuật toán đã bị bỏ qua trong thiết kế của AI. Thậm chí, có những trường hợp mà các nguyên nhân gây sai sót của AI không thể xác định được bởi các mô hình học máy quá phức tạp và ngay cả người lập trình ra nó cũng không thể giải thích được cách lý luật của mô hình, tạo ra hiệu ứng hộp đen
(blackbox)
.
Với trường hợp của xe Uber, hệ thống đã phân loại vật thể đi trước nó là “xe đạp”, sau đó loay hoay giữa “xe đạp” và “khác” trong vòng 1,5 đến 2,6 giây cuối cùng. Nó không xác định được chính xác có người đi cạnh chiếc xe đạp, cũng không dự đoán chính xác được đường đi của người đó. Dù hệ thống tự lái được thiết kế để cố gắng lái vòng qua chướng ngại vật bất kể nó được phân loại gì, nhưng AI quyết định nó không làm được điều đó và lựa chọn giảm tốc độ ở những giây cuối cùng. Người lái xe đã nhanh chóng nắm lấy vô lăng, khiến chiếc xe mất quyền tự chủ và chuyển sang chế độ thủ công, nhưng tất cả đã quá muộn.
AI có thể thiên vị
Để hiểu rõ hơn về những hậu quả của AI, chúng ta phải đặt câu:
Chính xác thì các hệ thống học máy hoạt động như thế nào?
PGS. Mai Tấn Tài giải thích rằng, về cơ bản bất kỳ hệ thống AI nào cũng được tạo ra từ ba phần: dữ liệu, thuật toán, và mô hình.
Các dữ liệu có thể phi cấu trúc hoặc có cấu trúc, cung cấp đầu vào cho việc phát triển AI. Ngay sau đó, các thuật toán sẽ tìm hiểu mối quan hệ tương quan trong dữ liệu và tìm ra các trọng số cho từng yếu tố. Cuối cùng là mô hình được đào tạo dựa vào những gì đã học được từ thuật toán để có thể ra quyết định khi được cung cấp dữ liệu mới.
Như vậy, dữ liệu là khởi nguồn của AI. Nhưng bản thân dữ liệu trong đó đã có sự thiên vị, bởi chúng do con người tạo ra và con người thì luôn có sự thiên lệch trong suy nghĩ, ứng xử và quyết định của mình. “Bạn hoặc con bạn có thể bị loại khỏi một cuộc tuyển chọn nhất định đơn giản chỉ vì bạn có một số đặc điểm khiến AI thiên vị bạn”, PGS. Mai Tấn Tài chia sẻ.
Mỹ và châu Âu đã có vấn đề với sự phân biệt chủng tộc, khiến người da màu bị loại khỏi các sự kiện, trường học hoặc công việc. Chẳng hạn như khi nhà tuyển dụng đặt câu hỏi với AI ‘Hãy giúp tôi đưa ra các tiêu chí để tìm một nhà phát triển AI giỏi’, hệ thống sẽ cung cấp các tiêu chí bao gồm màu da, vì tới 70% dữ liệu nó có về các nhà nghiên cứu AI hiện nay là người da trắng. Trên thực tế, không phải là người da trắng giỏi AI hơn người da màu, đó chỉ là do sự sẵn có của dữ liệu.
“Việt Nam có thể không gặp sự thiên vị về chủng tộc như thế, nhưng có thể sẽ vấp phải những vấn đề tương tự, chẳng hạn như về vùng miền, địa phương vì chúng ta đã có những ngầm định”, anh nói thêm.

Những nhà phát triển AI có thể hạn chế được phần nào những thiên kiến này bằng cách sử dụng dữ liệu sạch hơn, đại diện hơn; hoặc can thiệp vào các thuật toán AI để đảm bảo rằng các nhóm đại diện có đủ trọng số.
Nhưng làm thế nào để đưa việc xây dựng một AI có trách nhiệm như thế trở thành một tiêu chuẩn thay vì ngoại lệ? Để bắt đầu việc này, PGS. Mai Tấn Tài cho rằng điều đầu tiên là phải nhận ra có những thành kiến khác nhau có khả năng ảnh hưởng đến dữ liệu và chi phối các mô hình học máy. Không chỉ những người phát triển AI cần phải nhận thức được điều đó, mà cả những người sử dụng AI cũng phải hiểu rằng các thuật toán chỉ là thuật toán, và nếu đầu vào của nó đã có lỗi, đầu ra cũng sẽ không tránh khỏi sai lầm.
Theo anh, chúng ta không nên “thần thành hóa AI” như một công cụ hoàn mỹ. Đồng thời cũng cần “ít ngây thơ hơn” khi nghĩ AI chỉ là vấn đề của các nhà nghiên cứu, của chính phủ mà thực ra chúng đang liên quan mật thiết với mỗi người và ai cũng cần tìm hiểu về nó.
Kết hợp các thực hành đạo đức vào công nghệ AI
Trong thời đại ngày nay, việc sử dụng và phát triển AI dường như là hiển nhiên. Vì vậy, cần phải có các “khuôn khổ AI” để đảm bảo việc phát triển và sử dụng công nghệ này tuân theo các thực hành đạo đức.
Theo TS. Phạm Thanh Long, chuyên gia nghiên cứu về AI Ethics tại Trung tâm phân tích dữ liệu Insight của Đại học Tổng hợp Cork (Ireland), một khuôn khổ đạo đức trong lĩnh vực AI không nên chỉ là phần phụ của công nghệ mà phải được xem như một yếu tố dẫn dắt. Ở châu Âu, người ta đang cố gắng luật hóa các quy tắc về đạo đức AI, đặc biệt là về dữ liệu riêng tư của cá nhân, như một căn cứ để hướng dẫn các bên liên quan phát triển AI theo hướng cải thiện chất lượng cuộc sống và đảm bảo quyền con người.
Dự thảo
Đạo luật trí tuệ nhân tạo (AI Act)
của châu Âu đã đưa ra 7 yêu cầu chính để đạt được một hệ thống AI đáng tin cậy, bao gồm: phải có sự tham gia, giám sát của con người; phải đủ mạnh và an toàn để xử lý các lỗi; phải đảm bảo quyền riêng tư và quản trị dữ liệu; phải minh bạch, có thể truy suất nguồn gốc; phải đảm bảo sự đa dạng, không phân biệt đối xử và công bằng với các nhóm xã hội; nên được sử dụng để tăng cường phúc lợi xã hội và trách nhiệm môi trường; và phải có các cơ chế để đảm bảo trách nhiệm giải trình đối với các hệ thống AI và kết quả của chúng.
Các khu vực khác nhau sẽ có những ưu tiên khác nhau, TS. Phạm Thanh Long nhận xét, chẳng hạn OECD chỉ đưa ra năm yêu cầu, với EU là bảy (có thêm các yêu cầu về con người tham gia giám sát AI và bảo đảm quyền dữ liệu cá nhân).
“EU lấy câu chuyện quyền công dân cao hơn tất cả. Do vậy, những yêu cầu về sự tham gia của con người (Human agency & oversight) và các quyền riêng tư cá nhân (Privacy & Data governance) trong những hệ thống AI ở EU là rất quan trọng. Và nhiều khi ta thấy các quyền đó thoạt nghe cũng điên rồ và khó thực hiện, nhưng người ta vẫn phải làm và làm đến cùng để bảo vệ chúng”, chị nói.

Dự luật AI của EU đã đưa ra cách quản lý AI theo mức độ rủi ro của các sản phẩm đầu ra. Mức độ rủi ro của hệ thống AI đối với các quyền và sức khỏe của con người càng cao thì các quy định quản lý càng siết chặt hơn.
Có 4 cấp độ rủi ro. Các hệ thống được xếp vào dạng
‘rủi ro không thể chấp nhận được’
sẽ hoàn toàn bị cấm, không được phép bán trên thị trường EU, chẳng hạn như chấm điểm tín nhiệm xã hội, nhận diện gương mặt, sinh trắc học, giám sát bằng AI theo thời gian thực ở nơi công cộng v.v.
Các hệ thống
‘rủi ro cao’
như dùng AI trong quá trình tuyển dụng, tiếp cận dịch vụ tài chính, quản lý người lao động, thiết bị y tế, xe cộ, quản lý cơ sở hạ tầng quan trọng điện nước, dự đoán điểm trong giáo dục v.v phải tuân theo các nghĩa vụ nghiêm ngặt và trải qua các đánh giá về sự phù hợp trước khi được đưa vào sử dụng.
Các hệ thống có
‘rủi ro hạn chế’
được phép dùng nhưng bên triển khai phải có nghĩa vụ cung cấp thông tin và minh bạch, bao gồm chatbot, deepfakes, mô hình ngôn ngữ lớn, mô hình hình ảnh lớn và mô hình âm thanh lớn. Người dùng cần được thông báo rằng họ đang dùng một hệ thống AI trừ khi nó quá rõ ràng.
Cuối cùng, những hệ thống có
‘rủi ro tối thiểu hoặc không có rủi ro’
được thoải mái sử dụng mà không có hạn chế gì, chẳng hạn như các hệ thống đề xuất nội dung trên Youtube, Facebook, nơi mà người ta có thể chọn lờ đi những đề xuất mà mình không thích.
Đạo luật AI của EU không phải là luật lớn duy nhất luật hóa rủi ro AI. Trước đó, EU đã đặc biệt thông qua Quy định bảo vệ dữ liệu chung (GDPR), và một số luật mới như Đạo luật Dịch vụ Kỹ thuật số (DSA) và Đạo luật Thị trường Kỹ thuật số (DMA). Sắp tới, Chỉ thị trách nhiệm pháp lý của AI cũng có thể đóng vai trò quan trọng trong việc quản lý AI ở châu Âu.
EU đã tiến xa hơn Mỹ và Trung Quốc trong nỗ lực quản lý AI. Khối này đã tranh luận về chủ đề AI trong hơn hai năm và tình hình trở nên cấp bách hơn sau khi ChatGPT được phát hành vào cuối năm ngoái, làm gia tăng mối lo ngại về tác động tiềm ẩn của công nghệ AI đối với việc làm và xã hội.
Tại Mỹ năm ngoái, Nhà Trắng đã đưa ra các ý tưởng chính sách cũng dựa trên cách tiếp cận rủi ro, cụ thể theo ngành và phân tán cao giữa ba cơ quan liên bang. Mỹ cũng đưa ra các yêu cầu bảo vệ quyền riêng tư và thử nghiệm các thống AI trước khi triển khai rộng rãi cho người dùng. Có một số điều khoản của Mỹ trùng khớp với EU, mở ra cơ hội cho việc thiết lập một hành lang quản lý rủi ro AI xuyên Đại Tây Dương.
Tại Trung Quốc, dự thảo quản lý AI công bố hồi tháng tư năm nay sẽ yêu cầu các nhà cung cấp dịch vụ AI phải tuân thủ các quy định kiểm duyệt nghiêm ngặt. Trong quy định của Trung Quốc có những điều khoản đột phá mà các tranh luật quốc tế đang bàn tới, chẳng hạn như yêu cầu các nhà cung cấp thuật toán có thể "đưa ra lời giải thích" và "khắc phục" các tình huống trong đó các thuật toán đã vi phạm quyền và lợi ích của người dùng. Điều này có thể thúc đẩy các công ty AI của Trung Quốc thử nghiệm những phương pháp mới để giải thích thuật toán, một lĩnh vực còn rất non nớt trong học máy.
Khởi động cho Việt Nam
Việt Nam chưa xây dựng bất kỳ luật nào để điều chỉnh trí tuệ nhân tạo vào lúc này. Trước sự bùng nổ mạnh mẽ của ChatGPT, tại một cuộc hội thảo vào tháng hai năm nay, Thứ trưởng Bộ Giáo dục và Đào tạo Hoàng Minh Sơn cho rằng “còn quá sớm để nói về việc nên hạn chế hay khuyến khích ChatGPT trong giáo dục”. Trong khi đó, một số doanh nghiệp và các tổ chức giáo dục cho rằng “bây giờ không phải là lúc để lo lắng về việc kiểm soát các ứng dụng AI” mà bản thân con người cần phải “thay đổi và thích nghi với sự hiện diện của AI trong cuộc sống hằng ngày”,
VietnamNet
đưa tin.
Việc phát triển và sử dụng AI tại Việt Nam đang là một miền hoang dã và không có bất kỳ ràng buộc rõ ràng nào. Các công ty chủ động đưa ra công cụ AI theo những tiêu chuẩn đạo đức của riêng mình. Mặc dù là một nước có nhân lực công nghệ thông tin dồi dào, dân số gần 100 triệu người (đứng 15 thế giới) và tốc độ áp dụng AI vào cuộc sống nhanh chóng nhưng “Việt Nam chưa có nhiều tiếng nói về AI có trách nhiệm trên diễn đàn quốc tế”, TS. Phạm Thanh Longchia sẻ với phóng viên bên lề tọa đàm của
Tia Sáng
. Chị cho rằng hiện giờ là thời điểm thích hợp để Việt Nam bắt đầu nghĩ đến việc luật hoá các quy tắc về đạo đức AI.
Là một nước đi sau, Việt Nam có thể học được kinh nghiệm của những quốc gia đi trước như EU, Mỹ, Trung Quốc v.v. Nhưng các nhà nghiên cứu cảnh báo rằng không có tấm áo nào vừa cho tất cả. Việt Nam phải nhìn ngó tất cả để tìm ra những gì phù hợp cho riêng mình.
TS. Phạm Thanh Long so sánh, dù là hệ thống quản lý rủi ro đầu ra như EU hay hệ thống kiểm soát top-down như Trung Quốc đều có những điểm mù nhất định, chúng ta cần cố gắng tránh những điểm mù ấy. Trong khi đó, PGS. Mai Tấn Tài cho rằng có 2 khía cạnh liên quan đến AI là công nghệ và đạo đức, mà công nghệ thì phổ quát nhưng đạo đức lại đặc trưng theo từng cộng đồng nên rất khó để áp đặt các quy tắc đạo đức từ cộng đồng này sang cộng đồng khác.
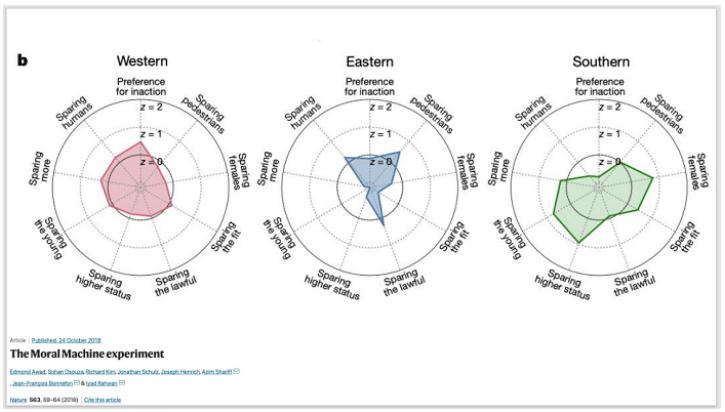
Anh dẫn chứng, trong một nghiên cứu trên
Nature
, các nhà khoa học đã làm một game nhỏ, thu hút hơn 40 triệu người ở hầu hết quốc gia trên thế giới để xem trong tình huống điều khiển xe mất phanh, gây ra cái chết của một số người nhất định – chẳng hạn như hai người đàn ông và một trẻ em, hoặc đánh lái đi thì ba người vô gia cư và một phụ nữ - thì họ sẽ lựa chọn những phương án nào. Kết quả cho thấy, những người ở khu vực phía Tây, phía Đông và phía Nam bán cầu có những xu hướng lựa chọn bảo toàn mạng sống của các đối tượng rất khác nhau.
Đạo đức, theo PGS. Mai Tấn Tài, là tập hợp các phép tắc hành xử để bảo vệ các giá trị mà mỗi cá nhân và cộng đồng đó coi trọng. Do vậy Việt Nam cần phải chủ động tìm ra những chuẩn mực xã hội mà chúng ta cho rằng AI nên phản ánh.
Bắt đầu từ quyền riêng tư
Dù chưa có luật riêng cho AI nhưng Việt Nam đã có những động thái quan trọng về bảo vệ dữ liệu cá nhân - “trái tim” của nhiều hệ thống AI. Sau bốn năm biên soạn,
Nghị định số 13/2023/ NĐ-CP
của Chính phủ về bảo vệ dữ liệu cá nhân đã chính thức có hiệu lực từ tháng bảy vừa qua, tạo hành lang pháp lý để giảm thiểu tối đa những nguy cơ và hệ quả của các hành vi xâm phạm dữ liệu cá nhân.
Theo quy định mới này, các doanh nghiệp, tổ chức xử lý dữ liệu sẽ phải có những biện pháp thích hợp để đảm bảo quyền của các chủ thể dữ liệu, bao gồm: quyền được biết, quyền đồng ý/rút lại sự đồng ý với dữ liệu, quyền xóa dữ liệu, quyền hạn chế xử lý dữ liệu, quyền yêu cầu bồi thường thiệt hại, và những quyền tự bảo vệ khác.
Dữ liệu cá nhân của công dân Việt Nam phải được bảo vệ và lưu trữ bí mật trong một thời gian thích hợp, cho mục đích xử lý dữ liệu xác định. Quan trọng nhất, chủ sở hữu dữ liệu phải được thông báo về bất kỳ việc xử lý dữ liệu nào liên quan đến họ. Những bên vi phạm sẽ phải đối mặt với các hình phạt hành chính hoặc hình sự.
TS. Phạm Thanh Long đánh giá, Nghị định 13 này có vai trò “cực kỳ tương tự GDPR”– luật bảo vệ dữ liệu cá nhân có hiệu lực từ năm 2018 và là nền móng vững chãi để EU xây dựng nên Đạo luật AI Act hiện nay. “Nếu được thực hiện tốt, nó sẽ là một cách hiệu quả để giảm thiểu rủi ro đạo đức khi phát triển và sử dụng các hệ thống AI ở Việt Nam”, chị nói.

Sẽ phải mất nhiều thời gian để những quy định về bảo vệ quyền riêng tư như thế này được áp dụng rộng rãi. Anh Lê Công Thành, Giám đốc Công ty công nghệ
InfoRe
về xử lý dữ liệu lớn và ứng dụng trí tuệ nhân tạo tại Việt Nam, tiết lộ: “Chúng tôi đã theo dõi Nghị định 13 từ khi chúng ban hành vào tháng tư và quyết định rằng để tuân thủ luật, chúng tôi phải đầu tư rất nhiều công sức để thay đổi hệ thống của mình. Chúng tôi phải xóa bỏ những dữ liệu thu thập, lấy mẫu được từ năm 2011 [lúc thành lập công ty] đến giờ. Các dữ liệu định danh thu thập từ kênh social media để giúp công ty phân tích, thống kê những vấn đề về dư luận cũng phải xóa bỏ hoặc mã hóa một chiều để không biết người dùng là ai.”
Vào thời điểm hiện nay, chưa nhiều doanh nghiệp “mạnh dạn” tuân thủ quy định về dữ liệu như InfoRe. Họ đang sở hữu một trong những
‘hồ dữ liệu’
lớn nhất nhì về truyền thông xã hội, và phải nâng cấp nó – thậm chí ngừng cung cấp dịch vụ trong gần một tháng - cho quá trình tuân thủ này.
Nhiều doanh nghiệp Việt Nam khác vẫn đang tiếp tục làm theo những biện pháp cũ và sử dụng dữ liệu một cách thoải mái, nhưng điều này sẽ sớm phải thay đổi. Với bất kỳ tổ chức, doanh nghiệp trong và ngoài nước nào đang hoạt động tại thị trường Việt Nam, nhiệm vụ trong vòng 6-24 tháng trước mắt sẽ là tìm cách chuyển biến các sản phẩm, dịch vụ của mình để di chuyển trong một môi trường số đòi hỏi những tiến bộ “rất giống với châu Âu.”
Nguồn: khoahocphattrien.vn















 Phần mềm Quản lý và tính toán tốc độ đổi mới công nghệ, thiết bị
Phần mềm Quản lý và tính toán tốc độ đổi mới công nghệ, thiết bị
 Phần mềm truy xuất nguồn gốc sản phẩm
Phần mềm truy xuất nguồn gốc sản phẩm
 Phần mềm quản lý văn bản và hồ sơ công việc
Phần mềm quản lý văn bản và hồ sơ công việc
 Phần mềm quản lý nhiệm vụ khoa học và công nghệ
Phần mềm quản lý nhiệm vụ khoa học và công nghệ
 Sàn giao dịch thương mại điện tử Hà Tĩnh
Sàn giao dịch thương mại điện tử Hà Tĩnh
dichvucong.png) Phần mềm Quản lý ATBX
Phần mềm Quản lý ATBX
 Hệ thống đánh giá chỉ số chuyển đổi số
Hệ thống đánh giá chỉ số chuyển đổi số
 Sàn giao dịch công nghệ và thiết bị trực tuyến Hà Tĩnh
Sàn giao dịch công nghệ và thiết bị trực tuyến Hà Tĩnh